
前回の記事では、GoogleのAI統合型IDE Antigravity と、環境管理の要である Miniconda(Python 3.11) を連携させ、開発の「土台」を磐石なものにしました。
しかし、「環境は整ったけれど、いざコードを書き始めようとすると何から手をつければいいのか分からない」と感じていませんか?
AI開発の学習において、最も重要なのは「最初の小さな成功体験」です。
高等数学やディープラーニングの理論はいったん横に置いて、まずはシンプルなコードでAIを動かし、「自分にもできる」という確かな自信を得ることが、継続への鍵となります。
本記事では、構築した環境を使い、AI開発の基礎を学ぶのに最適な「アヤメの品種分類」に挑戦します。
Pythonの標準的な機械学習ライブラリである scikit-learn を活用することで、わずかなコード量で95%を超える高い精度のAIモデルを作成し、AI開発キャリアの最初の成功を飾りましょう!
目次
第1章:データの準備と確認
本章では、学習に必要なデータセットをロードし、AIがどのような「情報」を使って分類を行うのかを確認します。
1.1. データセットのインポート
今回は、データサイエンスの学習用途で最も広く使われているアヤメ(Iris)のデータセットを使用します。
このデータセットは、機械学習ライブラリである scikit-learn に最初から組み込まれているため、外部からのダウンロードは不要です。
まず、プロジェクトフォルダ内に iris_ai.py というファイルを作成し、以下のコードを記述してください。
import pandas as pd
from sklearn.datasets import load_iris
pd.set_option('display.max_columns', None) # 表示する列数の上限をなくす
pd.set_option('display.width', 1000) # 画面幅を広く設定する
# 1. データセットをロード
iris = load_iris()
# 2. データの形状を確認
print("--- データ確認 ---")
print("データ(特徴量)の形状:", iris.data.shape)
print("ターゲット(品種)の形状:", iris.target.shape)このコードを実行すると、以下のような結果が表示されるはずです。
--- データ確認 ---
データ(特徴量)の形状: (150, 4)
ターゲット(品種)の形状: (150,)解説:AIが学習する「情報」の形
上記の実行結果は、AIが扱うデータが以下の形になっていることを示しています。
これは、線形代数で学ぶ行列の概念です。
- データ(特徴量)の形状
(150, 4): 150個のアヤメのサンプルがあり、それぞれのサンプルは4つの特徴(花びらとガクそれぞれの長さ・幅)を持っています。これがAIへの入力情報です。 - ターゲット(品種)の形状
(150,): 150個のサンプルそれぞれに対応する正解の品種データ(0, 1, 2の番号)が入っています。AIの正解データは、次のステップでPandasの表にした際に、target列として表示されます。
1.2. データを表形式で見てみる
人間にとって理解しやすいデータにするために、Pandasを使ってデータセットを表形式に変換してみましょう。
iris_ai.py に以下のコードを追加してください。
# 3. データをPandas DataFrameに変換して表示
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target
print("\n--- データの最初の5行 ---")
print(df.head())更新後のプログラムを実行すると、以下のような結果が表示されるはずです。
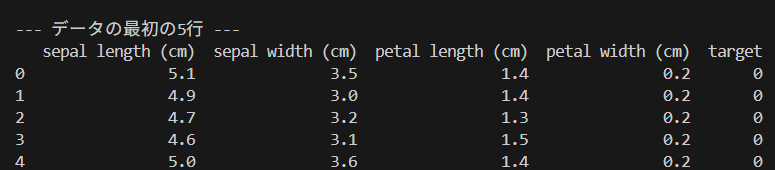
--- データの最初の5行 ---
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) target
0 5.1 3.5 1.4 0.2 0
1 4.9 3.0 1.4 0.2 0
2 4.7 3.2 1.3 0.2 0
3 4.6 3.1 1.5 0.2 0
4 5.0 3.6 1.4 0.2 0※ スマホの小さい画面では、上記の表が崩れるかもしれないので、画像形式でも提示しておきます。
AIが4つの数値(特徴量)を見て、品種(ターゲット)を予測する学習タスクに取り組むための準備が完了です。
次のステップでモデルを構築します。
第2章:モデルの訓練とテストデータ分割
AIモデルの学習に入る前に、モデルを公平に評価するための準備を行い、実際に学習させます。
2.1. 過学習を防ぐためのデータ分割
モデルを訓練したデータと同じデータで評価すると、モデルは「カンニング」をして高いスコアを出してしまいます。これを「過学習」と呼びます。
過学習を防ぐための手法はいくつかありますが、今回はデータを訓練用とテスト用の2つに分割する手法(ホールドアウト法)をとります。
iris_ai.py に以下のコードを追加してください。
from sklearn.model_selection import train_test_split
# 4. データとターゲット(正解)を準備
X = iris.data # 特徴量 (150, 4)
y = iris.target # ターゲット (150,)
# 5. データを訓練用(80%)とテスト用(20%)に分割
# random_state=42 は、データ分割のランダムな結果を固定し、毎回同じ結果を得るための設定です。
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
print("\n--- データ分割の形状 ---")
print("訓練データ数:", X_train.shape[0])
print("テストデータ数:", X_test.shape[0])💡 過学習を防ぎ、評価の信頼性を高める手法
- ホールドアウト法 (Hold-out Method)
- 仕組み: データセット全体を、モデルの訓練に使うデータ(訓練データ)と、モデルの評価に使うデータ(テストデータ)の2つに一度だけ分割します。
- メリット: 実装が非常に簡単で、計算コストが最も低いため、AI開発の最初のステップとして最適です。今回採用している手法がこれにあたります。
- 交差検証 (Cross-Validation)
データを一度だけ分割するのではなく、複数回分割と評価を繰り返すことで、評価結果の信頼性を高める手法です。- 仕組み: データセット全体を \(k\) 個のグループ(分割)に分けます。1つのグループをテストデータとして使い、残りの \(k-1\) 個のグループを訓練データとして使ってモデルを評価します。これを $k$ 回繰り返し、得られた $k$ 個の評価結果(例:精度)の平均値を最終的な性能評価とします。
- メリット: データセット全体を効率的に訓練と評価に使うことができ、データセットの偏りによる評価のブレを最小限に抑えられます。最も一般的なのは K-分割交差検証 (K-Fold Cross-Validation) です。
- 正則化 (Regularization)
モデルが訓練データに細かく適合しすぎるのを防ぎ、過学習を抑制するための手法です。- 仕組み: 訓練中に、モデルの複雑さ(各パラメーターの値の大きさ)に対して**ペナルティ(罰則項)**を与えます。これにより、モデルは訓練データに対する誤差を減らすだけでなく、パラメーターが不必要に大きくなるのを避けるようになり、結果としてシンプルな(過学習しにくい)モデルが生成されます。
- ドロップアウト (Dropout)
ディープラーニングにおいて、過学習を防ぐために使われる非常に強力な手法です。- 仕組み: ニューラルネットワークの訓練中に、**ランダムに選ばれた一部のニューロン(ノード)を一時的に無効(ドロップアウト)**にします。これにより、特定のニューロンに予測を頼りすぎることを防ぎ、ネットワーク全体がよりロバスト(頑健)に学習するようになります。
2.2. モデルの選択と訓練
AIモデルとしてロジスティック回帰を選択し、訓練データを使って学習させます。
iris_ai.py に以下のコードを追加してください。
from sklearn.linear_model import LogisticRegression
# 6. モデルの選択と初期化
model = LogisticRegression(max_iter=200)
# 7. 訓練データを使ってモデルを学習させる! (最も重要なステップ)
print("\n--- モデル訓練開始 ---")
model.fit(X_train, y_train)
print("モデル訓練完了!")第3章:モデルの評価と成功体験
この最終ステップでは、訓練に使っていないテストデータを使って、AIモデルがどれだけ正確に品種を予測できるかを評価します。
3.1. 予測と精度の確認
今回は、scikit-learnの標準関数を使わずに、Python(NumPy)の機能を使って予測精度を計算し、正解率をパーセント表示します。
iris_ai.py の最後のコードブロックを以下のように変更してください。
# 8. テストデータを使って予測を実行
y_pred = model.predict(X_test)
# 9. 正解率を計算 (NumPyの機能を利用)
# (予測値 == 正解値) でTrue/Falseの配列を作り、平均を取ることで正解率が計算
accuracy = (y_pred == y_test).mean() * 100.0
print("\n--- 評価結果 ---")
print(f"最初のAIモデルの正解率(Accuracy): {accuracy:.2f}%")💡 解説:NumPyによる正解率の計算
scikit-learnライブラリを使用しての開発では、通常、正解率を計算するには accuracy_score 関数を使いますが、上記のように記述することで、以下の高度なNumPyの処理をわずか一行で実現しています。
y_pred == y_test:予測結果と正解を比較し、一致していればTrue、間違っていればFalseの配列が生成されます。.mean():NumPyでは、Trueを1、Falseを0として扱います。この配列の平均を計算することで、「正解した割合」つまり正解率(Accuracy)が得られます。
実行結果は、おそらく 96.67% や 100.00% といった高い数値になるはずです。
--- 評価結果 ---
最初のAIモデルの正解率(Accuracy): 100.00%まとめ
今回の記事では、AntigravityとMinicondaの土台の上で、AI開発の全プロセスを経験し、初のAIモデルを完成させました。
作成したプロジェクトで、以下の重要な基本ワークフローを、自身のコードで実行することに成功しました。
機械学習のワークフローイメージ
しかしながら、実際のAI開発では、この「性能」をさらに高めなければなりません。
そのためには、以下の疑問に答える必要があります。
- ロジスティック回帰よりもっと強いモデルを使ったらどうなるのか
- データの前処理を工夫したら、もっと精度は上げられるのか
- そもそも、正解率100% というのは本当に優秀なAIと言えるのだろうか
次回の記事では、これらの疑問に答えるため、「性能改善」という実践的なテーマに焦点を当てます。


コメント