
AI開発の歴史に、巨大な転換点が訪れました。
OpenAIが提唱した「Open Responses」。
これは、バラバラだった各社のAI APIを、まるでUSB Type-Cのように一本の共通規格で繋ごうとする壮大な革命です。
それに伴い、本連載も、今日から「次世代ステージ」へと突入します。
今回実装するのは、単なる「ファイルの一括読み込み」や「上書き更新」だけではありません。
将来、AIの規格が世界標準に統一されても、設定を一つ変えるだけでそのまま使い続けられる「汎用的で強固な設計(アーキテクチャ)」へとアプリを刷新します。
これまでの「実験用の砂場」を卒業し、実際の開発現場でも通用する設計思想を取り入れましょう。
具体的には、開発フォルダを新しく作り直し、Anacondaの環境からライブラリまで、最新の標準に最適化して再構築します。
「一度作れば、未来まで使い続けられる」一生モノのAIアシスタントの基盤を、この激変する時代の最前線で完成させましょう。
目次
第1章:次世代ステージへの準備 ── 環境の刷新
「実用化」と「標準化」への対応。この2つを確実に実現するため、まずはまっさらな環境で土台を組み直します。
AntigravityとMinicondaをすでに導入済みの方は、「1.3. プロジェクトフォルダの刷新」まで進んでください。
1.1. Antigravityのダウンロードとインストール
AIによるコード生成やデバッグ、プロジェクト管理を行うための IDE として、Google製のIDE 「Antigravity」 を使用します。
こちらのサイトからダウンロードが可能です。
Antigravityは、VS Codeベースで開発された IDE なので、VS Codeユーザーであれば違和感なく使用することができます。
1.2. Minicondaの導入 ―― 開発の土台を整える
- Minicondaの公式サイトから、お使いのOS(Windows/macOS/Linux)に合ったインストーラーをダウンロードします。
- インストーラーの指示に従って進めます。特別な理由がなければ、インストールオプションはデフォルト設定のまま進めて問題ありません。
インストールが完了したら、Anaconda Promptを起動し、conda --versionと入力してバージョンが表示されれば成功です。
1.3. プロジェクトフォルダの刷新
将来的な拡張を見据え、専用の作業ディレクトリを作成します。
Windowsであればエクスプローラー、Macであればファインダーを使用して、任意の場所に「ai_app」というフォルダを作成してください。
私の場合は、以下の場所に作成しました。
※ ユーザー名は伏字(xxx)で表示していますので、自身の環境に読み替えてください。
C:\Users\xxx\ai\ai_app
1.4. 次世代標準に備えた「仮想環境」の作成
ここからは、Anaconda Promptを使用します。
本プロジェクト専用の仮想環境をフォルダ名と合わせて ai_app という名前で作成し、有効化(activate)する作業です。
Anaconda Promptを起動し、以下のコマンド(全5コマンド)を順次実行してください。
※1: 「#」から始まるコメント行は入力不要です。
※2: 最後の2つのコマンドは分単位で時間がかかる場合があります。
# 1. プロジェクトフォルダに移動
cd C:\Users\xxx\ai\ai_app
# 2. Python 3.11を指定して新しい仮想環境を作成
conda create -n ai_app python=3.11 -y
# 3. 作成した環境を有効化(毎回実行してください)
# 有効化に成功すると、行の先頭が (base) から (ai_app) に変わります
conda activate ai_app
# 4. 回答用モデル(Llama 3)をダウンロード
ollama pull llama3
# 5. 埋め込みモデル(物差し)をダウンロード
ollama pull mxbai-embed-large1.5. Antigravityの起動
フォルダと環境が整ったら Antigravity を Anaconda Prompt 経由で起動します。
# カレントディレクトリ(現在のフォルダ)を対象にAntigravityを起動
antigravity .この起動方法により、ai_app フォルダをプロジェクトとして開いた状態で、コードの記述や編集がスムーズに行えるようになります。
1.6. 必須ライブラリのクリーンインストール
ここからの作業は Antigravity で実施していきます。
Antigravityが起動したら、「Ctrl + @」(Macの場合はCmd + @)のショートカットを使いターミナルを開きます。
ターミナルが開いたら次のコマンドを実行してください。
pip install numpy pandas scikit-learn langchain-ollama langchain-chroma langchain-community langchain pypdf第2章:config.py の作成 ── 汎用性を考慮した設定ファイル
環境が整ったら、次は設定ファイルである config.py を実用版として作成します。
今回の目玉機能である「ファイルの一括読み込み」を実現するために、設定項目を編集します。
2.1. 設定ファイル「config.py」の変更
config.py を以下のとおりコーディングしてください。
config.pyMODEL_NAME = "llama3" # 使用するモデル名
EMBED_MODEL_NAME = "mxbai-embed-large" # 埋め込みモデル名
VECTOR_DB_PATH = "./chroma_db" # ベクトルデータベースの保存先
KNOWLEDGE_DIR = "./knowledge" # 知識ファイルを置くフォルダ
SOURCE_ID_KEY = "source" # 重複チェックに使用するIDのキー名続いて、設定した KNOWLEDGE_DIR に合わせ、実際にファイルを置く場所を作成しておきましょう。Anaconda Prompt で以下のコマンドを実行してください。
mkdir knowledge2.2. 設定項目の補足説明
- KNOWLEDGE_DIR(読み込みフォルダ):
- プログラムの中に直接「./knowledge」と書かず、設定ファイルで定義することで、将来的に「PDF専用フォルダ」や「Webサイトから取得したデータ用」など、読み込み元を変更したくなった際も、プログラム本体を汚さずに対応できます。
- この変更により、前回インポートしていた os モジュールは不要になります。
- SOURCE_ID_KEY(ID管理の鍵):
- 今回実装する「上書き更新」では、ファイル名をIDとして使います。
このIDをデータベースのどのラベル(キー)で管理するかを設定として持っておくことで、将来「Open Responses」などの共通規格でラベル名が指定された際も、ここを書き換えるだけで瞬時に対応が可能になります。 - 値として
sourceという文字列を指定する主な理由は、LangChainが自動で付けてくれる情報をそのままIDとして流用できるからです。
- 今回実装する「上書き更新」では、ファイル名をIDとして使います。
第3章:新生 ingest.py ── 知識ファイルの一括取り込みと「上書き」の実装
指定フォルダ内のファイルを読み込み、内容が更新されていれば上書きする「実用版」のプログラムを新規に作成します。
これまでの「プログラムコード内で1行ずつ登録する」方法からは卒業です。
3.1. ingest.pyの完成コード
Antigravityで新しいファイル ingest.py を作成し、以下のプログラムをコーディングしてください。
ingest.pyimport config
from langchain_community.document_loaders import DirectoryLoader, TextLoader
from langchain_text_splitters import CharacterTextSplitter
from langchain_chroma import Chroma
from langchain_ollama import OllamaEmbeddings
def main():
# 1. 知識フォルダ(knowledge/)からテキストファイルを一括読み込み
print(f"Loading files from: {config.KNOWLEDGE_DIR}...")
loader = DirectoryLoader(
config.KNOWLEDGE_DIR,
glob="**/*.txt",
loader_cls=TextLoader,
loader_kwargs={'encoding': 'utf-8'}
)
raw_documents = loader.load()
if not raw_documents:
print("No files found. Please add .txt files to the knowledge folder.")
return
# 2. 長い文章を適切な長さに分割(=チャンク化する)
text_splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=20)
documents = text_splitter.split_documents(raw_documents)
# 3. 埋め込みモデルの準備
embeddings = OllamaEmbeddings(model=config.EMBED_MODEL_NAME)
# 4. ベクトルDBの準備
vectorstore = Chroma(
persist_directory=config.VECTOR_DB_PATH,
embedding_function=embeddings
)
# 5. ファイル名をIDとして上書き保存
print("Ingesting documents with Upsert logic...")
for doc in documents:
file_id = doc.metadata.get(config.SOURCE_ID_KEY)
# 同じIDがあれば更新、なければ新規追加
vectorstore.add_documents(documents=[doc], ids=[file_id])
print(f"Done! Ingested {len(documents)} chunks from {len(raw_documents)} files.")
if __name__ == "__main__":
main()3.2. 動作確認:テスト用の知識ファイルを作って実行する
コードが書けたら、実際に動かしてみましょう。
ここでは「AIに新しい知識を覚えさせる」という最初の成功体験を目指します。
Antigravity、またはメモ帳などで以下の内容のファイルを作り、knowledge フォルダの中に保存してください。
- ファイル名:my_knowledge.txt
- 内容:興味対象についての任意の文章
- 例:マイルス・デイヴィスのアルバム『Kind of Blue』は1959年に録音されたモダン・ジャズの金字塔です。『Kind of Blue』には、ピアニストのビル・エヴァンスが参加しており、モード・ジャズという手法を確立しました。マイルスの別の名盤『Bitches Brew』は1970年3月にリリースされ、エレクトリック・ジャズ(フュージョン)の先駆けとなりました。
知識ファイルが作成できたら、ingest.py を実行してください。
ターミナルにエラーが出ておらず、メッセージの最終行に以下の実行結果が表示されていれば成功です。
Done! Ingested 1 chunks from 1 files.第4章:新生 ask.py ── 次世代規格への対応を考慮した対話システム
質問用プログラムも、最新のライブラリ形式に合わせて新規作成しましょう。ChatOllama を採用し、より賢く、より標準に近い形に進化させます。
4.1. ask.pyの完成コード
Antigravityで新しいファイル iask.py を作成し、以下のプログラムをコーディングしてください。
ask.pyimport config
from langchain_chroma import Chroma
from langchain_ollama import OllamaEmbeddings, OllamaLLM
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
def main():
# 1. データベース(記憶)の読み出し
embeddings = OllamaEmbeddings(model=config.EMBED_MODEL_NAME)
vectorstore = Chroma(
persist_directory=config.VECTOR_DB_PATH,
embedding_function=embeddings
)
# 2. AI(考える脳)の準備
llm = OllamaLLM(model=config.MODEL_NAME)
# 3. 検索の仕組みを定義(Retriever)
# 上位3つの情報を参照するように設定
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
# 4. 回答のテンプレート(指示書)
template = """以下の「参考情報」を元に、質問に日本語で答えてください。
【参考情報】
{context}
【質問】
{question}
"""
prompt = ChatPromptTemplate.from_template(template)
# 5. 処理の流れ(チェーン)を構築:LCELスタイル
# 検索 -> プロンプト作成 -> AI回答 -> 文字列変換
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
print(f"\n[AIアシスタント準備完了] モデル: {config.MODEL_NAME}")
print("終了するには 'exit' と入力してください。")
# 6. 対話ループ
while True:
query = input("\n質問をどうぞ:")
if query.lower() in ["exit", "quit", "終了"]:
break
if not query.strip():
continue
print("回答生成中...")
# 実行(invoke)
response = chain.invoke(query)
print(f"\n[AIの回答]\n{response}")
print("-" * 30)
if __name__ == "__main__":
main()4.2. 動作確認:AIに質問してみる
さあ、いよいよここまで来ました。動作確認を実施してみましょう。
ask.py を実行すると、質問を促すメッセージが表示されます。
先ほど ingest.py で覚えさせたマイルス・デイヴィスの情報について(独自の知識ファイルを作成した方はその内容に応じて)質問してみてください。
緊張の瞬間です。
以下のように質疑応答の対話が完了できれば成功です。
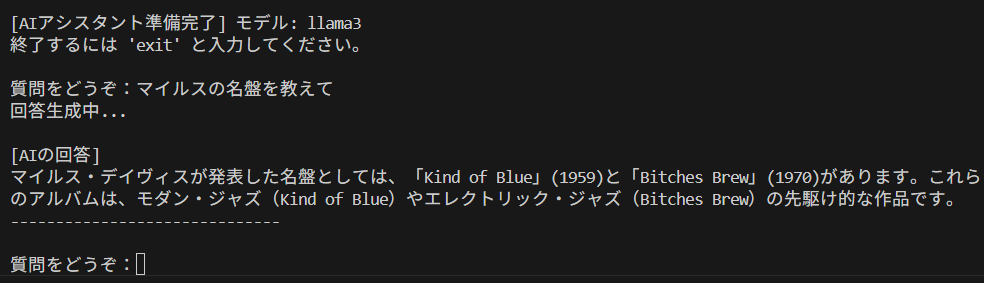
知識として作成した knowledge.txt から情報を適切に読み取って回答していることが分かります。
この結果は大成功と言えますね。
第5章:まとめ ── 我々が手に入れたもの
本記事を通じて、私たちはプロの開発現場でも通用する「知識の土台」と「AI開発環境」を手にしました。
5.1. 今回の成果
- 環境の分離(Miniconda): OSを汚さず、AI専用の部屋(
ai_app)を作ることで、どんなにライブラリが変わっても壊れない土台を作りました。 - 「最新の書き方」への適応(LCEL): 古い関数を使わず、データの流れを可視化するパイプライン形式で書くことで、拡張性の高いシステムになりました。
- 知識管理の実用化 :今回の
ingest.pyの完成により、もうプログラムを書き換える必要はありません。覚えさせたい知識を書いたテキストファイルをknowledgeフォルダに放り込むだけで、AIはそれを自動的に自分の知恵として取り込みます。
5.2. 次のステップ:知識の「量」と「質」を広げるアイディア
これで、あなたのPC内に「自分だけの知識を持ったAI」が誕生しました。
現状ではテキストファイル(.txt)だけですが、この仕組みは思っている以上に拡張性に富んでいます。
今後の記事でアップデート候補となるアイディアをいくつかリストアップしておきましょう。
- PDFやExcelを読み込ませる: 会社の資料や取扱説明書をそのままAIに渡せるようになります。
- Webサイトの情報を参照する: URLを指定するだけで、最新のニュースやブログ記事をAIが学習します。
- より大規模なデータベースへの拡張: 数千、数万という膨大な資料を瞬時に検索できるようになります。
5.3. 最後に
AIは、誰かが用意してくれる魔法などでは決してありません。
1行1行のコードと、正しい環境、そしてほんの少しの粘り強さがあれば、個人プログラマーでも創造できる『道具』です。
本シリーズを通して、それを実感できた読者が一人でもいたならば、執筆した甲斐があります。


コメント